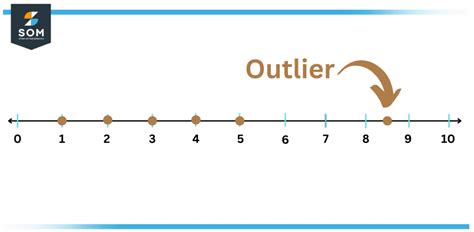
In the world of data analysis and statistics, the concept of an outlier often raises more questions than it answers. An outlier is a data point that significantly differs from other similar points. It can arise due to variability in the data or experimental errors. Understanding outliers is critical because they can skew data interpretation and lead to misleading conclusions. This article dives into the intricacies of what an outlier is, how to identify them, and how to manage their presence effectively in your datasets.
Key Insights
- Outliers can distort the perception of data and lead to incorrect conclusions.
- Technically, outliers are values that deviate significantly from the overall trend.
- Effective handling of outliers involves thorough investigation and thoughtful decision-making.
Understanding Outliers: Definitions and Detection
Outliers are not merely random anomalies but have their place in statistical analysis. They are data points that stray far from the central tendency, such as the mean or median, and may indicate variability in the data. There are several methods for identifying outliers, ranging from simple visual tools like box plots to more complex statistical methods such as Z-scores. A robust approach often combines these techniques. Box plots, for example, use quartiles to show the range, median, and potential outliers in a dataset, making them visually intuitive for preliminary outlier detection.Impact and Implications of Outliers
The presence of outliers can have significant implications on statistical analyses. For instance, in regression analysis, outliers can severely impact the line of best fit, skewing the results and leading to overfitting or underfitting. This distortion can result in poor model performance and unreliable predictions. In practical terms, an outlier can represent an error in data collection or an extreme but valid observation. For example, a dataset measuring household incomes might include an outlier of a multi-millionaire, representing a legitimate, albeit rare, occurrence. Therefore, the primary step in handling outliers involves determining whether they are measurement errors or valid extreme values. This discernment is crucial before making decisions about their treatment, such as exclusion or transformation.What should I do if I find an outlier?
If you encounter an outlier, first investigate its nature. Determine whether it’s due to an error in data collection or if it represents a genuine, albeit extreme, observation. If it’s valid, consider using robust statistical methods that are less sensitive to outliers. If it’s erroneous, review your data collection process and correct the issue.
Can outliers be removed?
Removing outliers should be approached with caution. Outliers can provide valuable insights into the dataset and its variability. It’s often more appropriate to keep them and apply robust statistical methods that mitigate their influence rather than outright removal, unless you are certain they result from errors.
Recognizing and managing outliers is essential for sound data analysis and interpretation. By understanding the mechanisms behind outliers and employing the right detection and handling techniques, you can ensure your analyses remain accurate and reliable. Remember, outliers are not always bad; they can reveal critical aspects of your data that merit deeper investigation.